publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
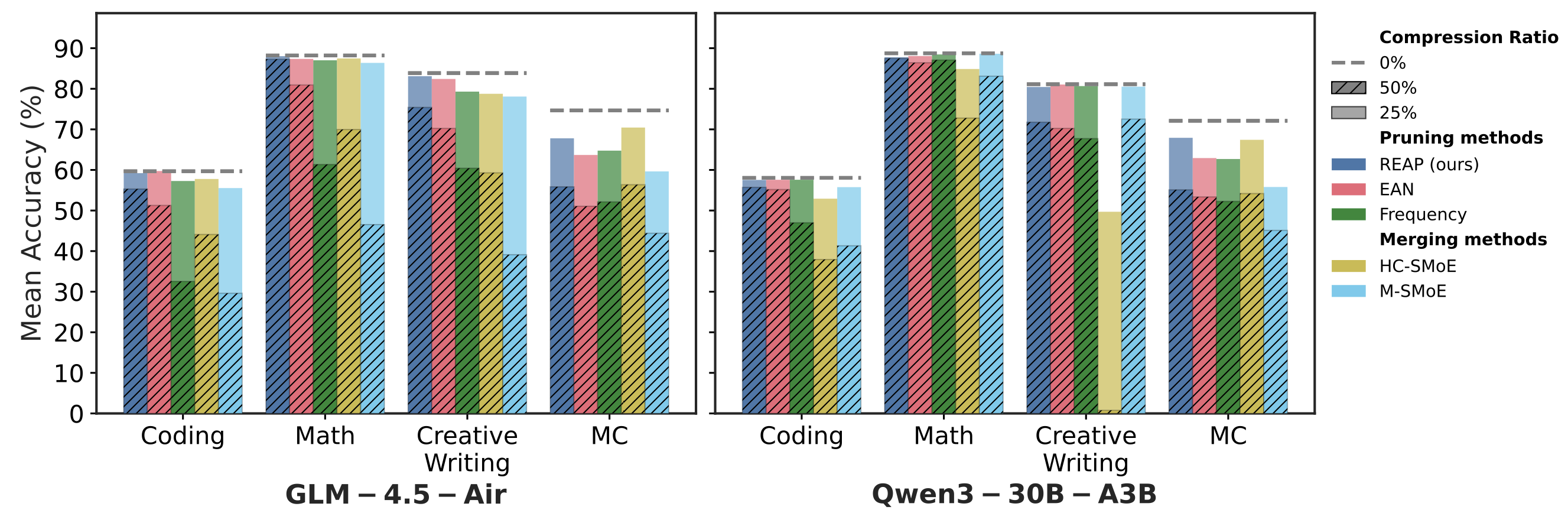
- Unmasking the Hidden Fairness, Bias, and Safety Costs of Compression with Mixture-of-Expert ModelsIn ICML 2026 Workshop on Trustworthy AI for Good, Jul 2026
- The Surprising Effectiveness of Deleting Weights in LLM Reasoning and AdaptationIn ICML 2026 Workshop on Foundations of Deep Generative Models: Understanding Memorization, Generalization, and Reasoning, Jul 2026
- Learning Parameter Sharing with Tensor Decompositions and SparsityTransactions on Machine Learning Research, Jun 2026To appear in TMLR
-
-
2025
- Trustworthy and Responsible AI for Human-Centric Autonomous Decision-Making SystemsTransactions on Machine Learning Research, Aug 2025
- A Study of Large Language Models for Extraction of Themes from Homeless Shelter Case NotesIn Third Workshop on Socially Responsible Language Modelling Research (SoLaR) 2025, COLM Workshops, Oct 2025
- Backdooring VLMs via Concept-Driven TriggersIn Data in Generative Models - The Bad, the Ugly, and the Greats (DIG-BUGS), ICML Workshops, Jul 2025
- Exploring Functional Similarities of Backdoored ModelsIn ICML Workshop on Technical AI Governance (TAIG), Jul 2025
- SD^2: Self-Distilled Sparse DraftersIn ES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models, ICML Workshops, Jul 2025
- Understanding Normalization Layers for Sparse TrainingIn 3rd Workshop on High-dimensional Learning Dynamics (HiLD), ICML Workshops, Jul 2025
- Backdooring VLMs via Concept-Driven TriggersIn Women in Machine Learning Symposium, ICML Workshops, Jul 2025
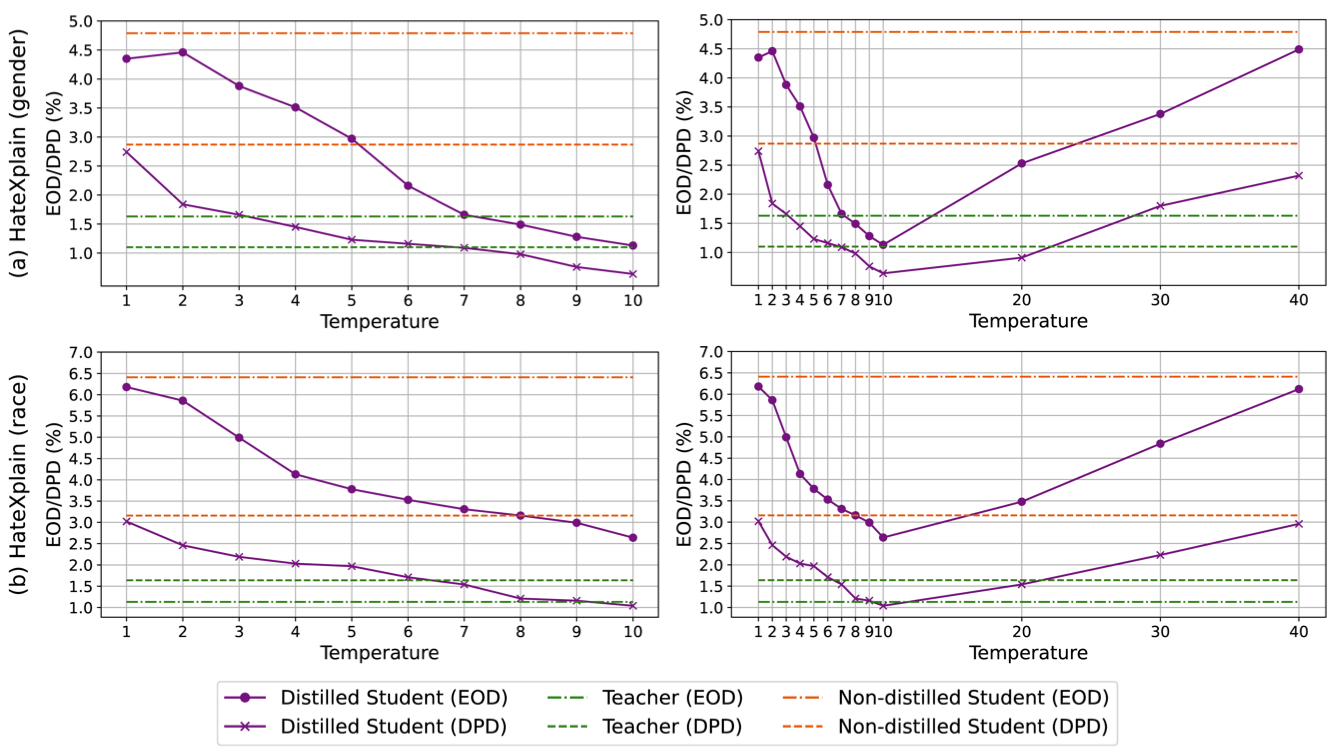
- Does Compression Exacerbate Large Language Models’ Social Bias?In 4th Muslims in ML (MusiML) Workshop, ICML Workshops, Jul 2025
-
-
2024
- Long-Tail Learning with Language Model Guided CurriculaIn Muslims in ML (MusIML) Workshop, NeurIPS 2024 Workshops, Dec 2024
- A Closer Look at Sparse Training in Deep Reinforcement LearningIn Muslims in ML (MusIML) Workshop, NeurIPS 2024 Workshops, Dec 2024
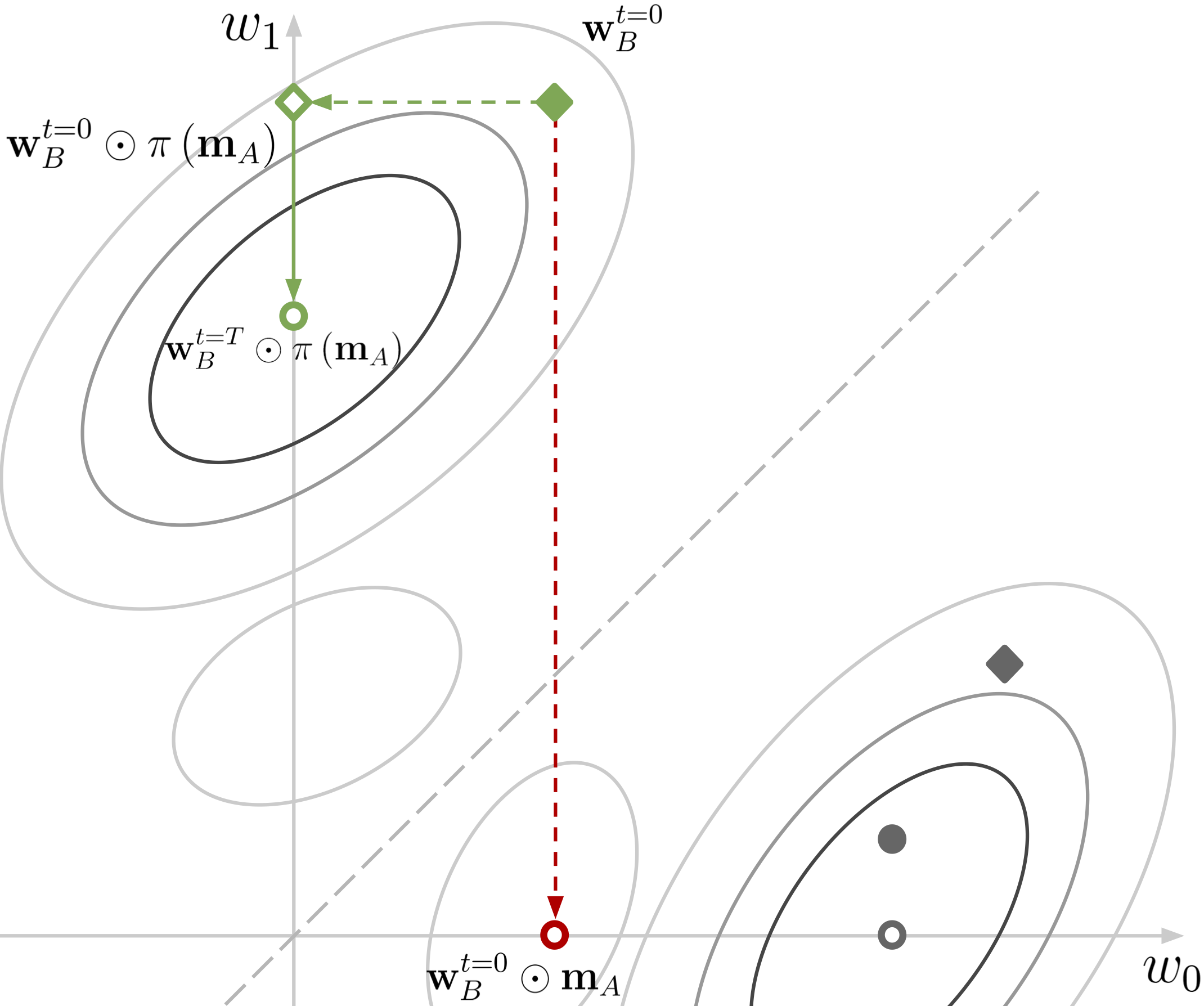
- Winning Tickets from Random Initialization: Aligning Masks for Sparse TrainingIn 2nd Workshop on Unifying Representations in Neural Models (UniReps), NeurIPS 2024 Workshops, Dec 2024
-
-
-
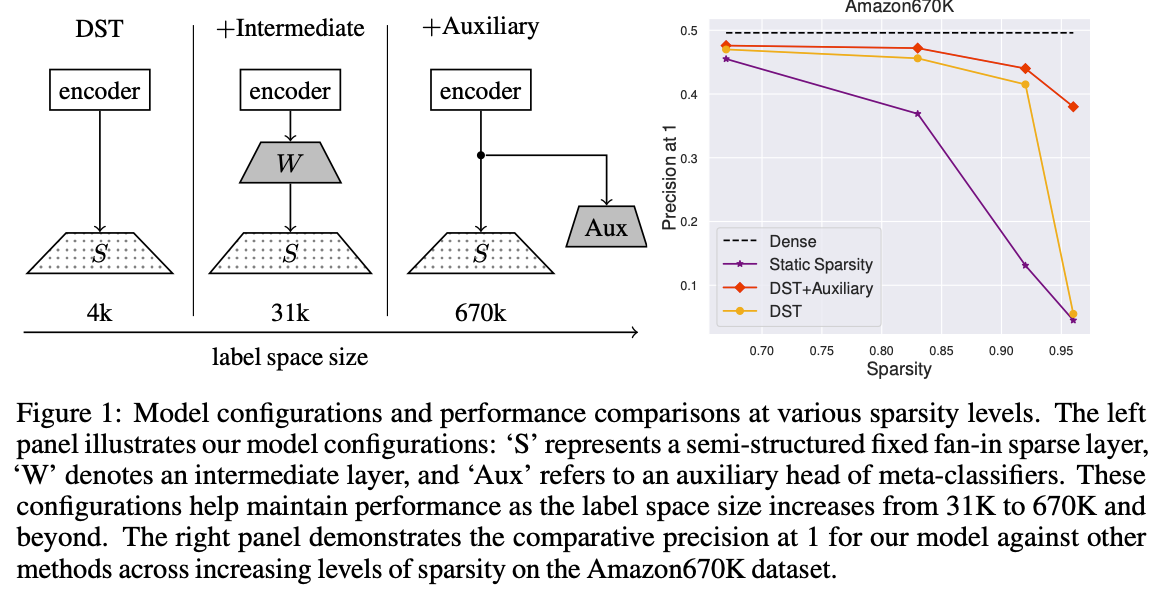
- SelfXit: An Unsupervised Early Exit Mechanism for Deep Neural NetworksTransactions on Machine Learning Research (TMLR), Oct 2024
-
- Classification Bias on a Data DietIn Conference on Parsimony and Learning (CPAL) Recent Spotlight Track, Jan 2024
2023
- Bounding generalization error with input compression: An empirical study with infinite-width networksTransactions on Machine Learning Research (TMLR), Jan 2023